What is inference?
Large Language Models (LLMs) are built and deployed in two phases. The first phase requires GPU hardware and a large amount of data to train the models. The second phase deploys the models to run inference queries, where the models can generate responses based on questions they have not seen before.
What is the Inference Cluster?
The ARC Inference Cluster is comprised of multiple nodes that behave as a single multi-threaded machine with a load balancer, tailored to run inference jobs efficiently, as shown below:
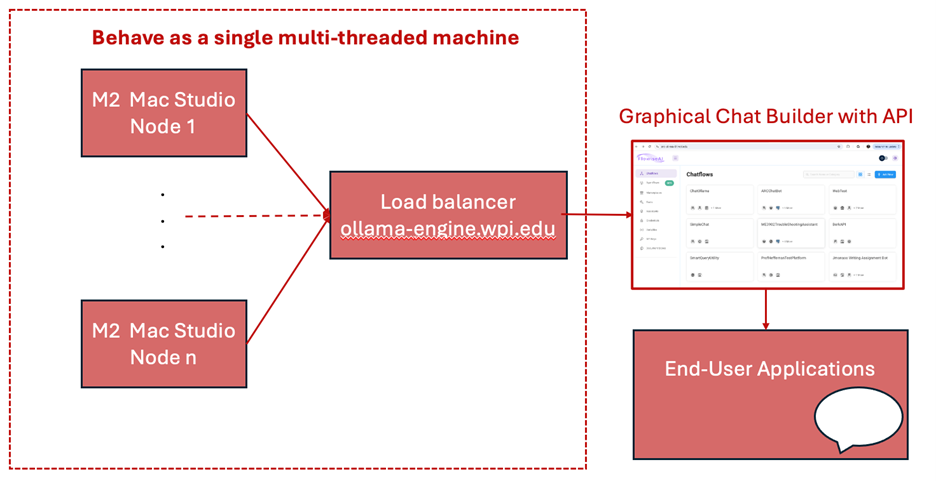
Why might I use the Inference Cluster?
Overall, there is increasing interest to deploy models for research projects. Once you have trained a model (i.e.: Llama 3 or a custom model), you may wish to host your model on our Inference Cluster.
If you are building an application that needs some form of intelligence, you may wish to use our resources for hosting as well.
How can I access and use the Inference Cluster?
We will work with you to host the model and provide API access using JavaScript or Python:
import requests API_URL = "https://arc-ai-rag-01.wpi.edu/api/v1/prediction/UNIQUEIDENTIFIER"
def query(payload): response = requests.post(API_URL, json=payload)
return response.json() output = query({ "question": "Hey, how are you?", })How can I get started with hosting my own LLMs?
Please request a consultation using the link below and describe the need. If the form does not appear on the Consultations page, please sign in with your WPI account in another tab in the same browser and reload the page.
Last Updated on August 13, 2024